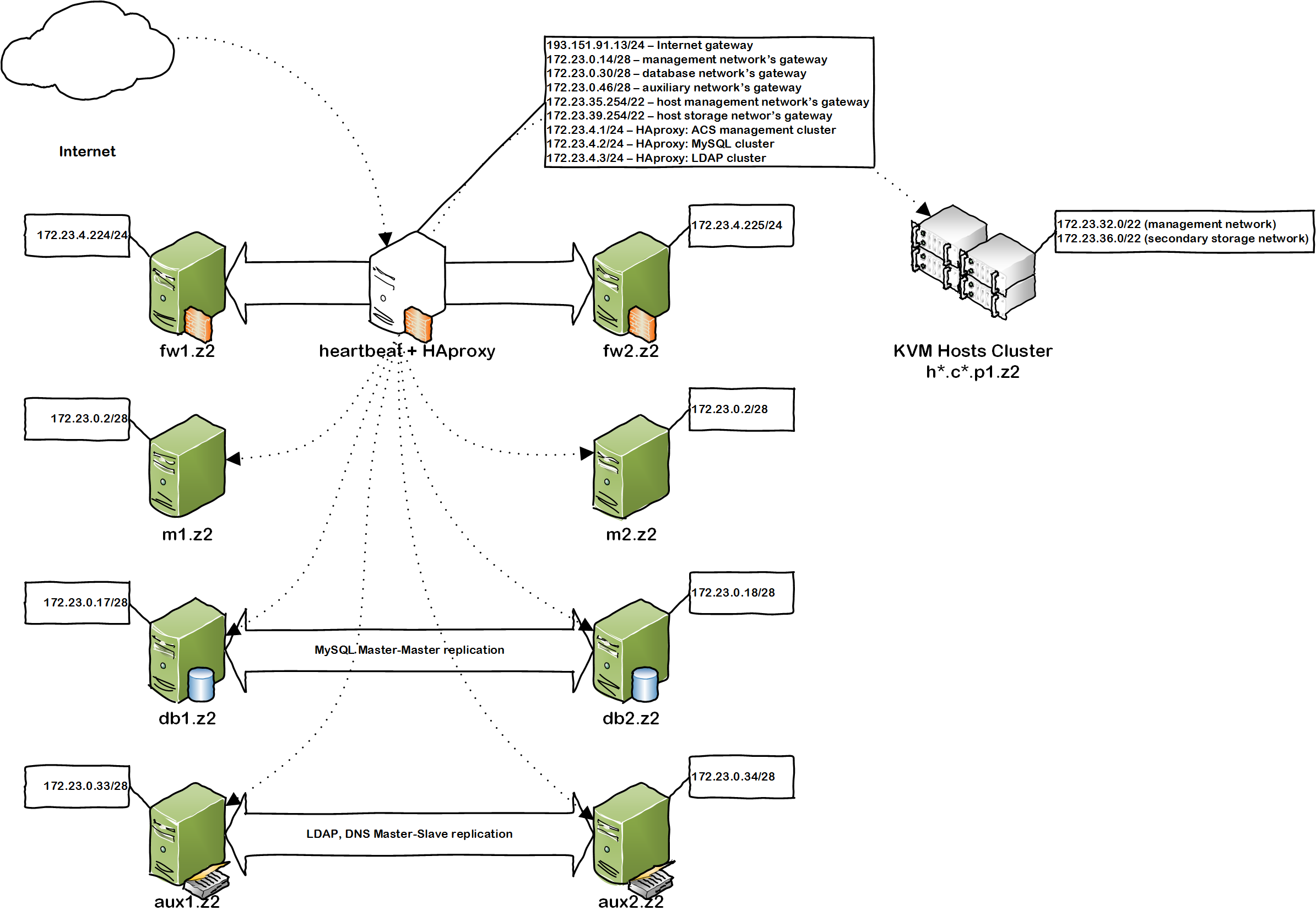
Creating and removing snapshots in Apache CloudStack with a neat schedule
Here’s an example of the configuration file of my make_snapshots.pl script based on the MonkeyMan framework.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 |
<timings> rest 60 # How much time to rest between iterations refresh 3600 # How often to rebuild the full infrastructure tree </timings> <timeperiod NEVER> period NONE </timeperiod> <timeperiod ALWAYS> period second{0-59} </timeperiod> <timeperiod NIGHT> period hour{23-5} </timeperiod> <timeperiod zaloopa13> period hour{0-3} weekday{1-3} period hour{4-7} weekday{4-6} period hour{12} weekday{7} </timeperiod> # We can define a domain's configuration by its ID <Domain by-id:* /> # But it's much more convenient to use their names, right? ;-) <Domain by-path:ROOT*> available ALWAYS # That's obvious frequency 86400 # Make a snapshot each 1 day keep 2 # Keep the last 2 snapshots, remove oldest </Domain> # And yes, we can use wildcards! <Domain by-path:ROOT/CUSTOMERS/*> available NIGHT frequency 86400 keep 3 </Domain> # Some customers requirements' could be sophisticated... <Domain by-path:ROOT/CUSTOMERS/zaloopa13> available zaloopa13 frequency 3600 keep 1000 </Domain> <Volume by-id:*> # We can inherit parameters from the related elements <inherit> # All volumes inherit the frequency and keep parameters # from the domains they belongs to, the values will not # be overriden by the inherited parameters... <Domain> frequency careful keep careful </Domain> # ...but we would like to override the parameters' values # from the virtual machine that the volume is attached to <VirtualMachine> frequency forced keep forced </VirtualMachine> </inherit> </Volume> <VirtualMachine by-id:* /> <VirtualMachine by-instancename:i-13-666-VM> keep 10 # Yes, we want the last 10 snapshots for this VM! </VirtualMachine> # We don't want to create a snapshot on the host where are more than 2 # snapshots in the Creating state or at least one snapshot in the BackingUp # state <Host by-id:*> available ALWAYS flows_creating 2 flows_backing_up 1 </Host> # We don't want to bother the local storages in a day <StoragePool by-name:*.tucha13.net Local Storage> available NIGHT flows_creating 2 flows_backing_up 1 </StoragePool> # Although a shared storage can do a lot of work! <StoragePool by-name:*.tucha13.net Shared Storage> available ALWAYS flows_creating 10 flows_backing_up 5 </StoragePool> |
Frankly speaking, I really can’t imagine how to deal with snapshots without this utility. 😛
I’d be happy to to know who else uses this script 🙂